[Draft] Proposal for Data Next-Generation¶
Status: DRAFT | WAITING FOR APPROVAL
Overview¶
The draft version of proposal contains various topics that are grouped into 6 component:
-
Review the current stage of the data operation.
-
Draft version of component for next-generation data platform.
-
Estimate budget for propose assets and infrastructure investment
-
Team structure and team capacibility.
Note:
Shorcut terms:
| Shortcut | Description |
|---|---|
| I, We, Our team | Represented for data team |
Current stack of our infrastructure¶
Our infrastructure now in version 3, which now on stable status on cloud.
| Version (v1) | Version (v2) | Version (v3) |
|---|---|---|
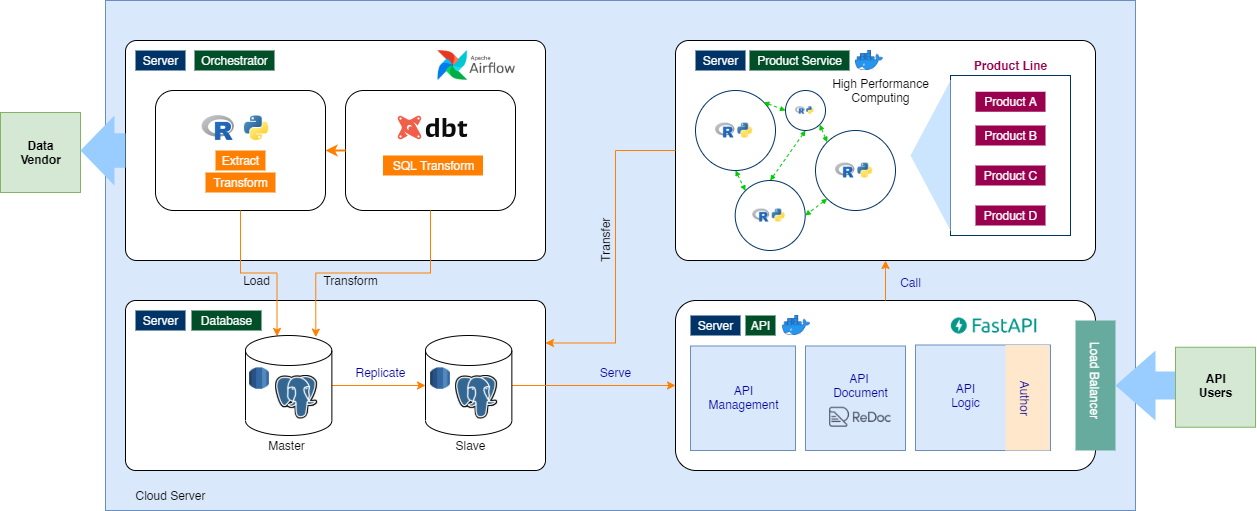 | 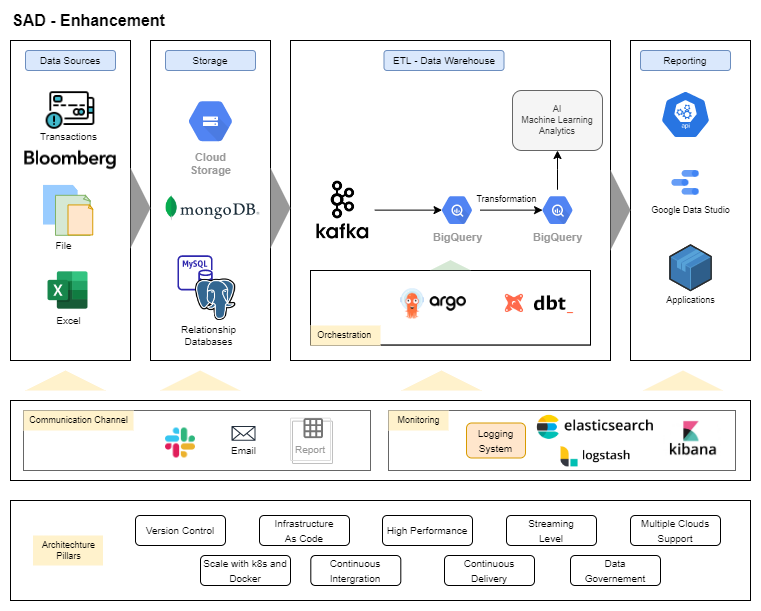 |  |
Target Pillars¶
Our design focus on:
Pillars on Infrastructure¶
[1] Design modern data stack platform with focused data areas
Modern tech stack has been introduced and expanded through the time, but the component for the system still the same.
| From AWS perspective | From Simform perspective |
|---|---|
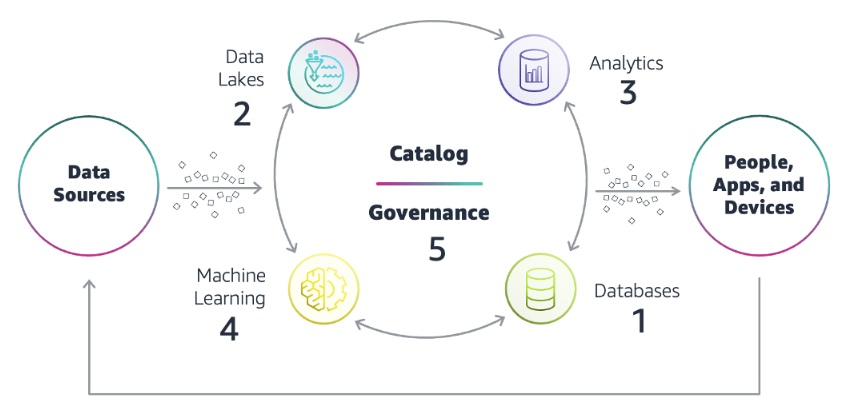 | 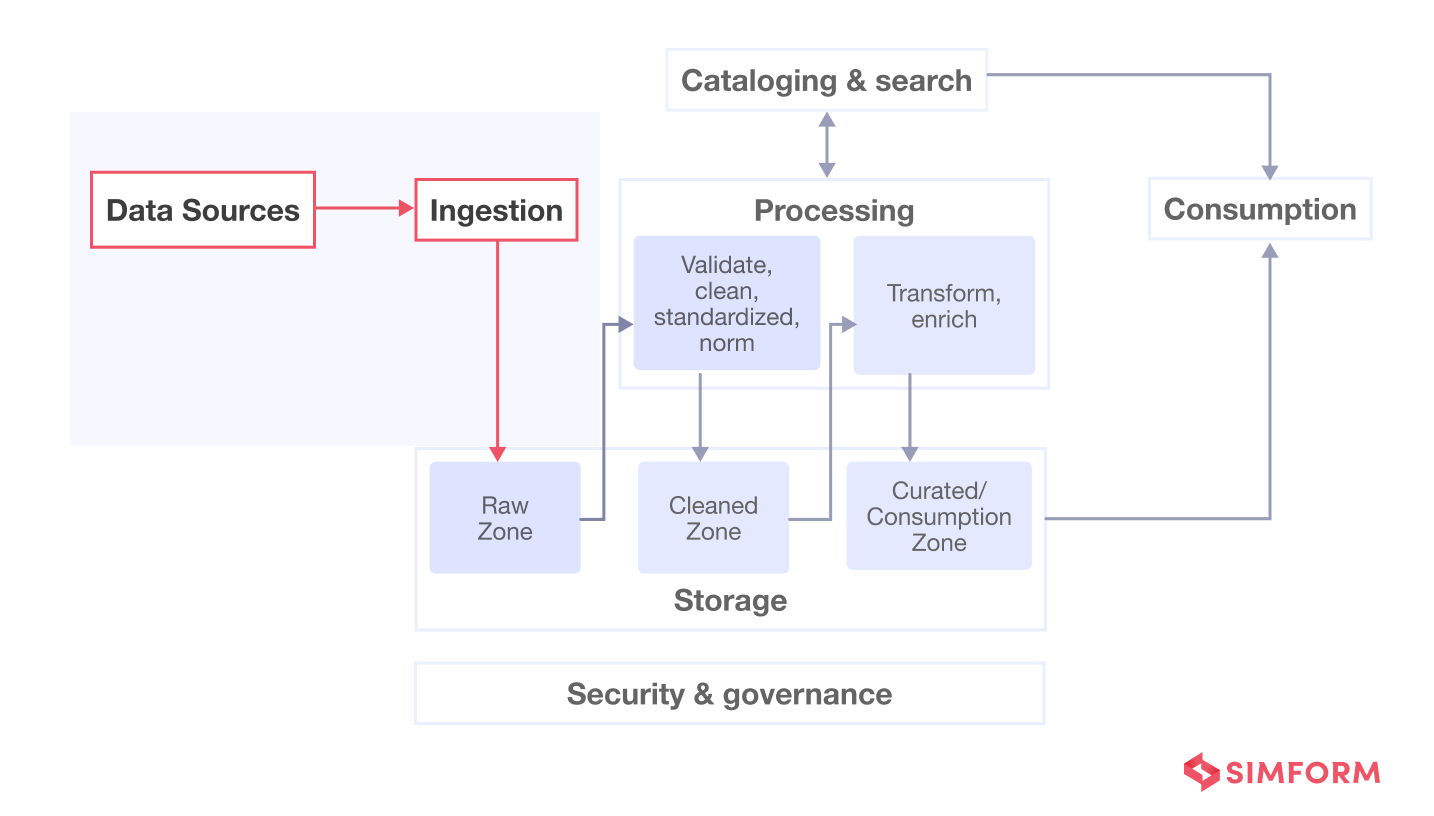 |
| Concepts of AWS modern data stack |
So that, we focus on areas, mainly seperated by following components:
| Key Component | Description |
|---|---|
| Data Ingestion | Batch, streaming data from various providers (or sources) into basement areas |
| Data Transformation | Converting, cleansing, and structuring data into a usable format that can be analyzed 2 |
| Catalog & Data Government | Governance data with support internal users |
| Access Government | Handle security in the component |
| Data Serving | Serve marts dataset into client or internal usage |
Based on the concepts, we want to archive the following key benefits:
-
Build scaleable architechtures that can handle explosive data growth and velocity.
-
Enable user [internal (data scientist), client] to intergrate with the system with ease.
-
The modern data architecture enables better business agility. It analyzes data and helps organizations gain insights as events happen in real time. By using purpose-built analytics services in a modern data architecture approach, data consumers can create business value by experimenting fast and responding to changes quickly.
-
All personas are empowered to use the best-fit analytics services.
-
The modern data architecture enables unified governance, which provides a secure, compliant, and auditable environment for data analytics workloads.
-
Centralized management of fine-grained permissions empowers security officers.
[2] Build scratch models for financial market
Based on the introduction from Google 3, we moving into the next level of data products design with models perspective.
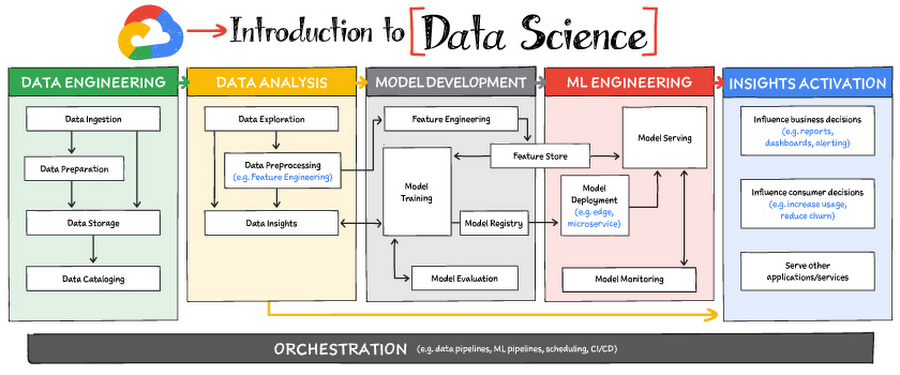
[3] Build our platform for:
-
[I] Data Observibility: control data life-cycle.
-
[II] Data Oschestration: schedule tasks with more convention.
-
[III] AI & Machine Learning Platform with MLOps deployment: build/training machine learning models
[4] Build (which mean a lot of internal tasks) over Buy (more services, and comes with cost) stategies
[5] Design/Implement the security for servers/services/database and on the journeys of the data teams
Pillars on Dataset¶
At the current stage, based on current landscape:
flowchart TB
%% Dataset
dataset[DataSet]
profile[Profile]
fundamental[Fundamental]
techical[Technical]
news[News]
social[Social Listening]
signal[Signal]
%% Flow
dataset --> profile & fundamental & news & social & techical --> signalWe focus on:
-
Signal help investor to trading has more persective on trading investment decision
-
Expand in vertical (more derived datasets) and expand horizontal (increase the coverage range landscape)
-
Support on the investment strategy
Suggested from FinGPT, we has a conceptual for datasets
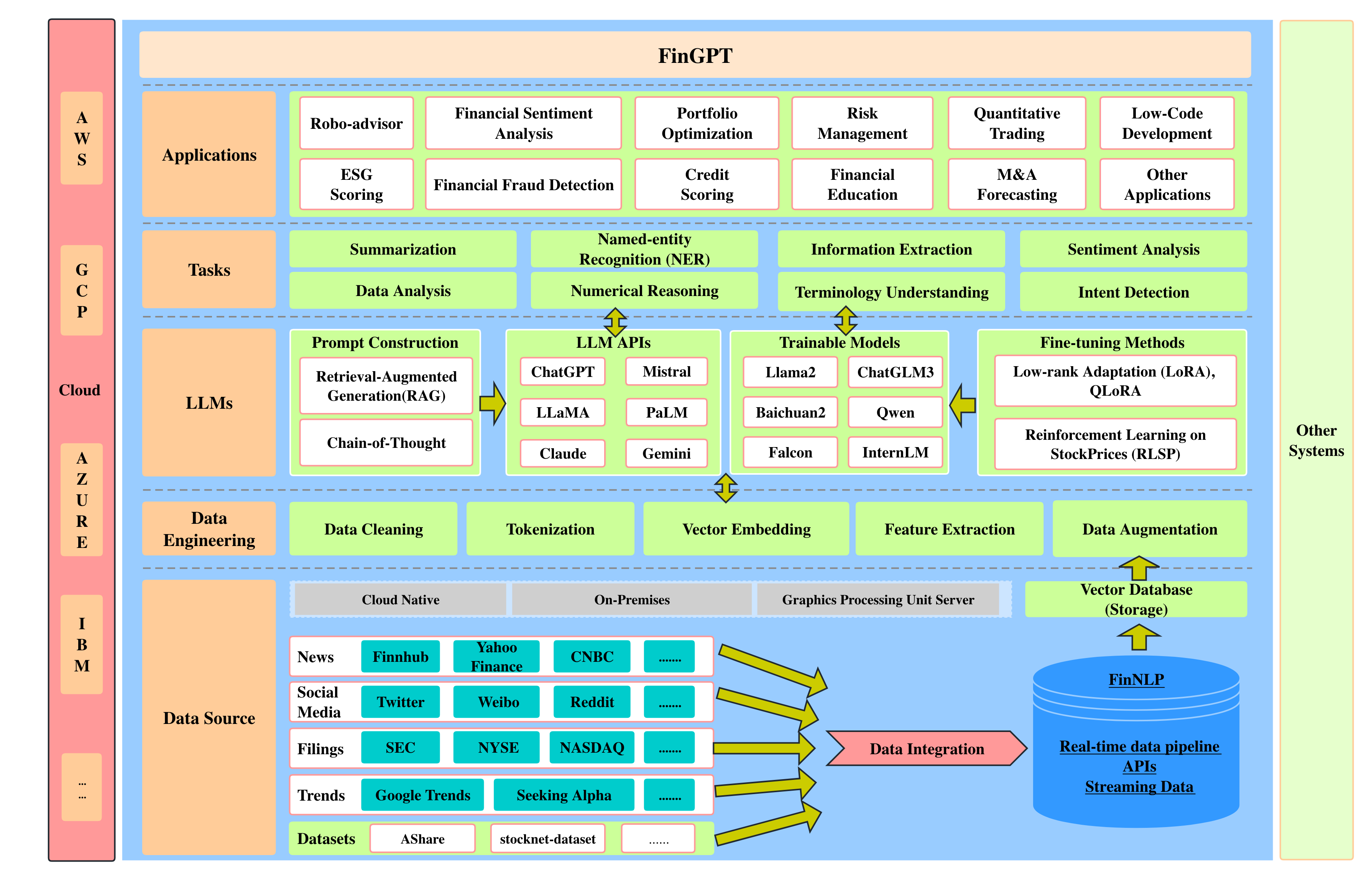
Target Initiatives¶
Focus on various initiatives seperated into 6 main block with 20 initiatives
The summary table detail for the initiatives
| Block | Initiative | Description | Detail |
|---|---|---|---|
| [1] Data enrichment | |||
| 1 | Data enrichment | Enrich dataset with touch point controller | Go to |
| 2 | Data Governmance Framework | Design blocks on governence datasect | Go to |
| [2] Data Platform | |||
| 3 | Big data-pipeline architechture | Design infra pipeline component | Go to |
| 4 | Oschestration Framework | New oschestration: Prefect | Go to |
| 5 | AI && Machine Learning, Computer-Vision models | Build models from ML framework | Go to |
| 6 | Data lake, Distributed framework | Framework on distributed system | Go to |
| 7 | Data mining | Mining datasets on the current landscape | Go to |
| [3] Data Project | |||
| 8 | Bump versions scheme of validation and API framework | Handle dependencies with focus on performance | Go to |
| 9 | Close gap between domain knowledge and technical | Progress with more documenation and release docs | Go to |
| 10 | API Service | API components design concept | Go to |
| 11 | Transfer service | Handle serving datset between columnars and rdms | Go to |
| [4] Data Monitoring | |||
| 12 | Data Pipeline Linkage and Linear | Monitor pipeline within multiple projects, services | Go to |
| 13 | Monitoring with Logging Agent and Prometheus | Monitor systems both on-prems and cloud | Go to |
| [5] Data Security | |||
| 14 | Security | Define/Implement security on project level and datasets | Go to |
| 15 | CICD for data-pipeline | CICD to increase the velocity of deployment and integration | Go to |
| 16 | Cloud Developers Folder | for seperated environment on testing infrastructure | Go to |
| [6] Development Resource | |||
| 17 | Documentation Platform | Selection for internal documentation | Go to |
| 18 | GitHub | Selection on GitHub enterprise | Go to |
| 19 | Communication | Selection on Communication channel | Go to |
| 20 | Project Software Development Tool | Proposal for Linear | Go to |
Based on current landscape of our project, here is the flow concepts that linked internal in the infrastructrue. Which can known as the process on build scalable pipeline.
flowchart LR
%% Component
subgraph comp1[:1:]
oschestration[Oschestration]
end
subgraph comp2[:2:]
api_internal[API internal]
end
subgraph comp3[:3:]
lake_processing[Lake Processing]
end
subgraph comp4[:4:]
transfer_snapshot[Transfer]
end
subgraph comp5[:5:]
api_consume[API consume]
end
subgraph comp6[:3:]
operation[Internal Operation]
end
%% Flow
comp1 --> comp2 --> comp3 --> comp4 --> comp5
comp6 --> comp2And based on that, our team based on a lot of underlying component.
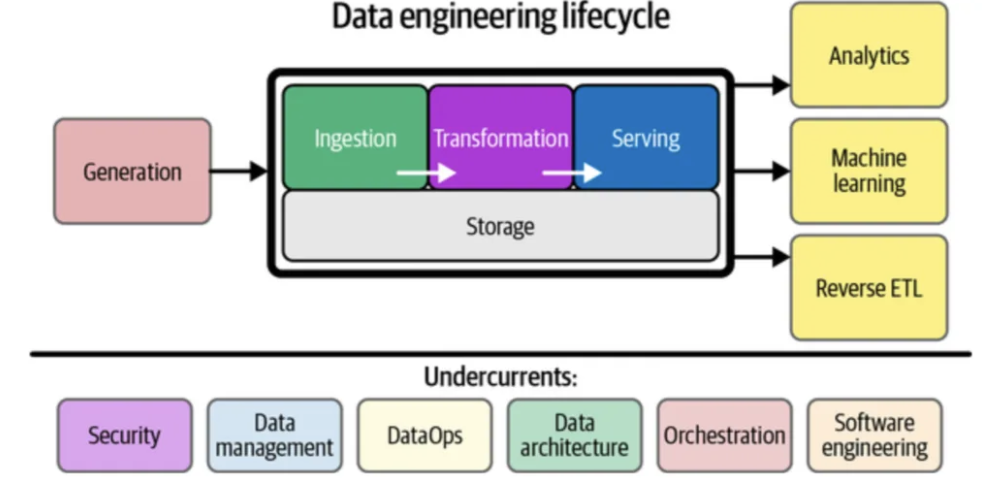
Block: Data Enrichment¶
[1] Initiative: Data enrichment¶
-
Focus on built component between batch and streaming job
-
Focus on intergrate more datasets from: Files, Images, Doumentation with frameworks
-
Integrate finance domain into the process to build dataset
-
Focus on financial tasks.
-
Build related system to control SLA for the datasets. E.g: Example question from Montecarlo - Data Ingestion
(a) What is the business need?
(b) What are the expectations for the data?
© When does the data need to meet expectations?
(d) Who is affected?
(e) How will we know when the SLA is met and what should the response be if it is violated?
[2] Initiative: Data Governmance Framework¶
Based on Aster.Cloud 1, we request on:
-
Data management, including data and pipelines lifecycle management and master data management.
-
Data protection, spanning data access management, data masking and encryption, along with audit and compliance.
-
Data discoverability, including data cataloging, data quality assurance, and data lineage registration and administration.
-
Data accountability, with data user identification and policies management requirements.
And on that, we focus on design
| Component | Description |
|---|---|
| Distributed Test Framework DTF | (a) Testing on multiple environments (b) Centralized platform |
| Pipeline Linkage Checkpoint | (a) Detect the linkage (b) YAML control the output of the pipeline |
| Data Governance Framework | Following building block from Aster Cloud introduction 1 and Montecarlo montecarlodata-data-ingestion |
Block: Data Platform¶
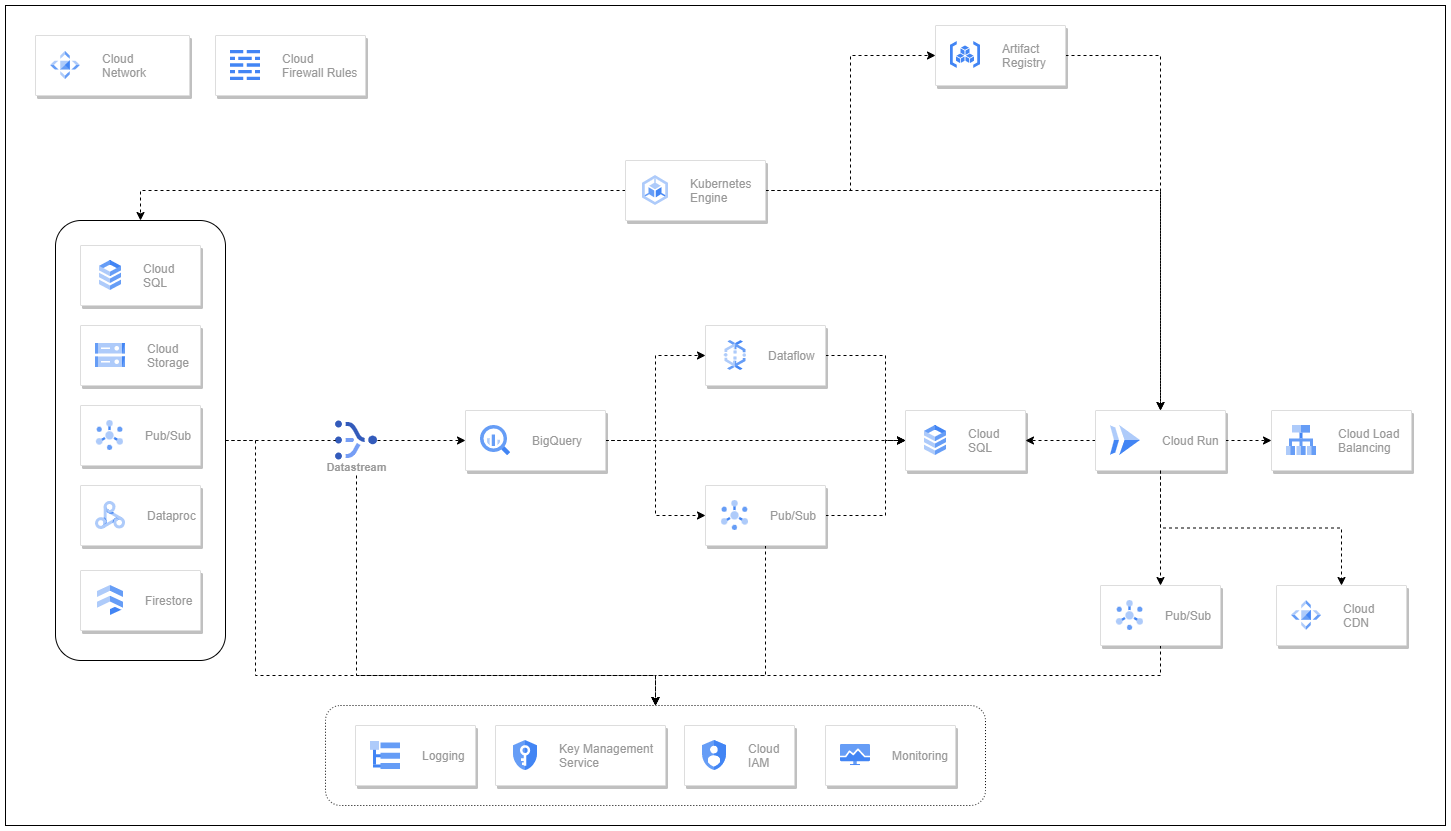
[3] Initiative: Build data-pipeline architechture with comprehensive buckets for data-* to join the analytics ground¶
The Ml4Devs has been introduced the big-picture for the components that we will prepair
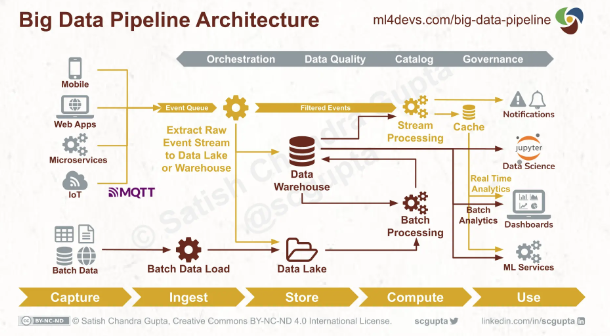
-
Notebook: for development in the on-prem machine (Jupiters)
-
MlOps: CICD from GCP
-
MLFlow: Tracking Experiments Set
-
Dataproc: Cluster for server with supported of Apache products
-
Data Version Control (DVC)
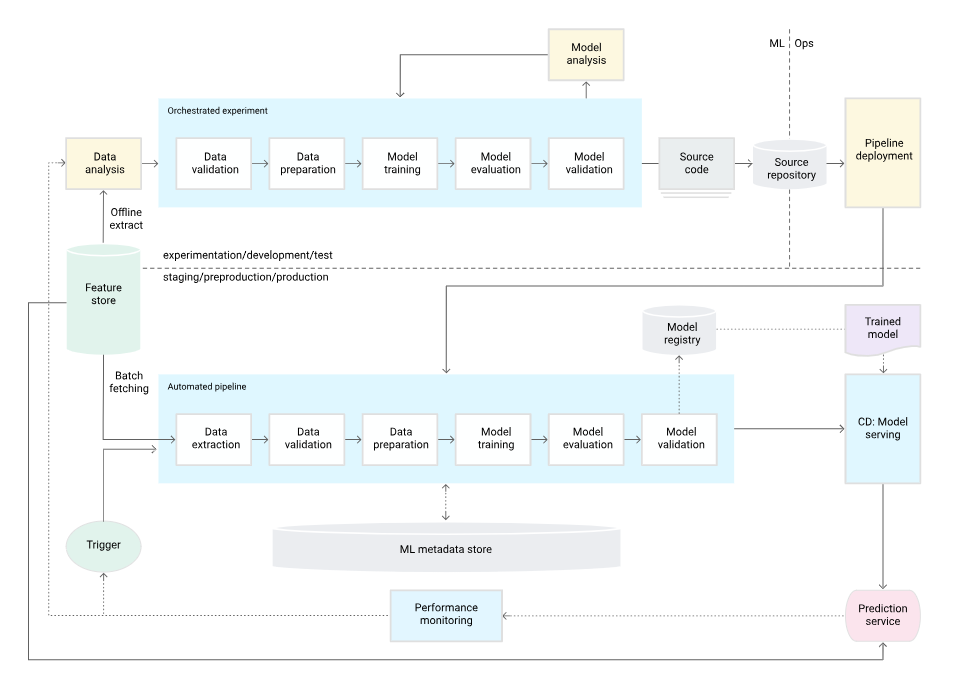
Based on gcp-continuous-in-machine-learning, we transition into level 1 of MLOps process
[4] Initiative: Oschestration Framework¶
After considering the comparasion of 11-data-orchestration-tools we specific for next oschestation tools is Prefect:
Here is some best-feature of Prefect
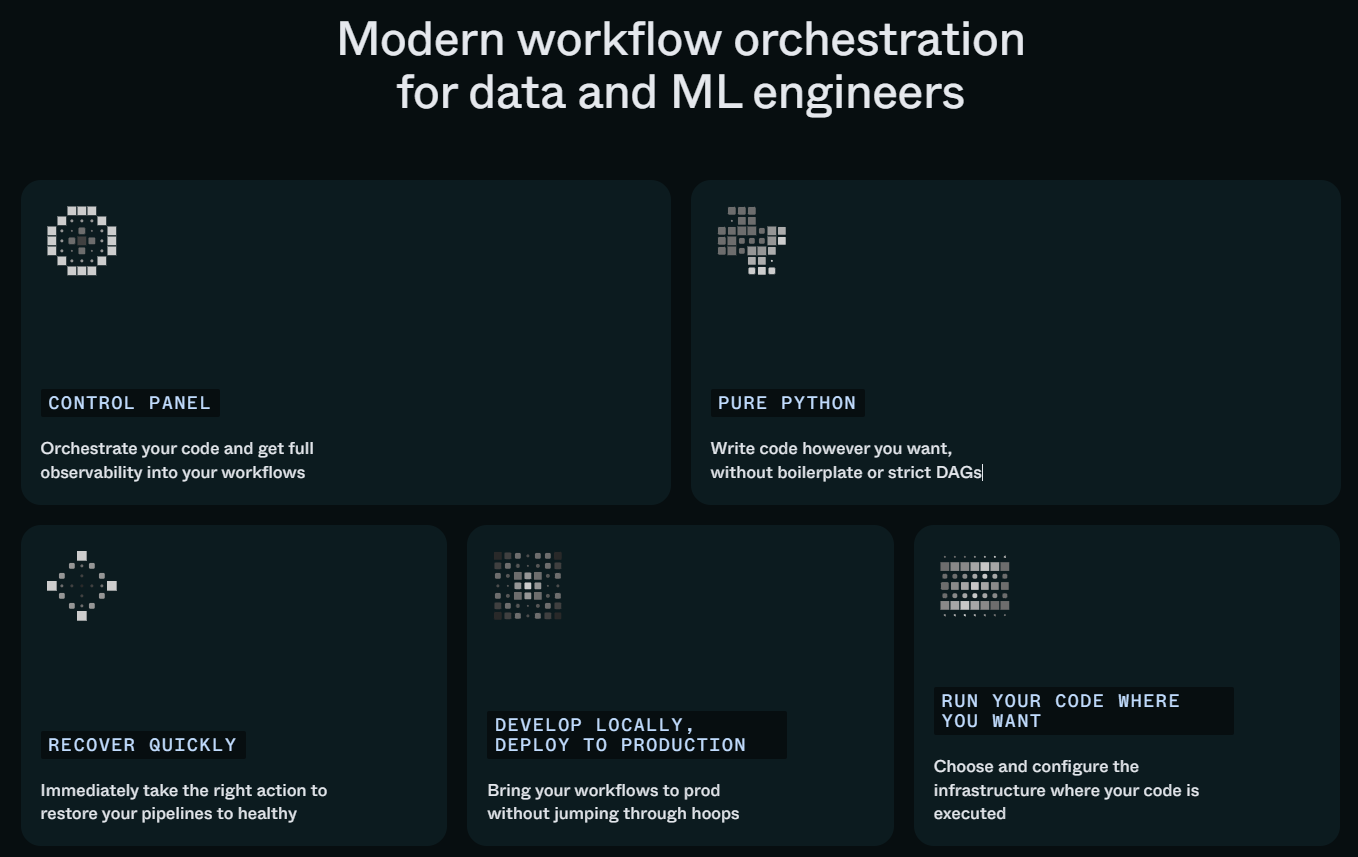
and come with:
-
OSS deployment and supported of our engirneering team
-
Configuration the infrastructure with on-prem and Cloud Run job (serverless)
[5] Initiative: AI && Machine Learning, Computer-Vision models¶
Set up a basic process system with the design of ML models and related infrastructure, and serve it into the current dataset system.
For models, it is possible to shape:
a) Build NLP models: NER, Sentiment
b) For time-series dataset: Used to determine the level of abnormal trading process phenomena
[6] Initiative: Data lake, Distributed framework¶
[7] Initiative: Data mining¶
Block: Data Project¶
Based on current project, we need to moving on the current landscape of dependencies and integrate services to archive performance.
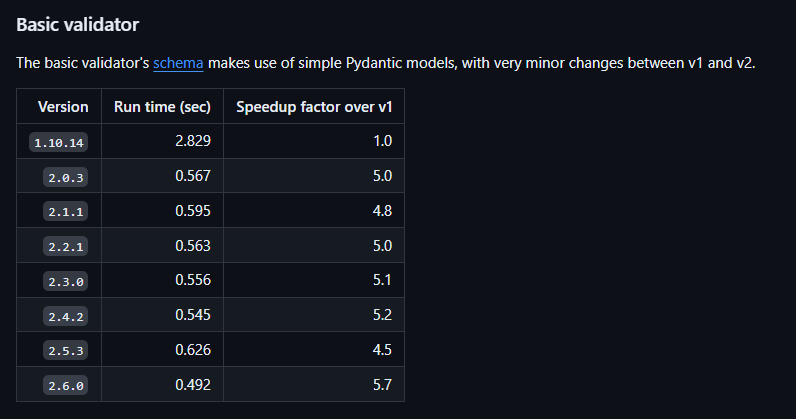
[8] Initiative: Bump versions scheme of validation and API framework¶
For almost internal package, we moving into:
-
Analytics:
polars,pandas -
Schema:
pydantic -
API Framework:
fastapi -
Updated the performance by updated version of API framework and Pydanctic version
[9] Initiative: Close gap between domain knowledge and technical (both tools and elements)¶
More transparency the black box interpret with the stakeholders
[10] Initiative: API Service¶
-
Establish the enteprise component
-
Serving more assets from CDN
-
Applied database as code: Atlas OSS. Introduction at here
-
With authentication method with matrix of permissions
-
Handle cache server related component
-
Handle documentation with supported endpoint
Example on Holistics Python API application repository on API
[11] Initiative: Transfer service¶
or using new related componnent to archive the performance and integrated component
Transfer using incremental or other integration
Block: Data Monitoring¶
[12] Initiative: Data Pipeline Linkage and Linear¶
-
Control the resources with more specific
-
YAML control and test the system
[13] Initiative: Monitoring with Logging Agent and Prometheus¶
Logging helps capture critical information about events that occurred within the application
Tracks system performance data to ensure proper working of the application
Captures any potential problems related to suspicious activity or anomalies
Helps debug/troubleshoot issues faster and easier
Monitoring provides holistic view into application SLAs with log aggregation
Insights into application performance and operations
Real-time alerts and tracking dashboards
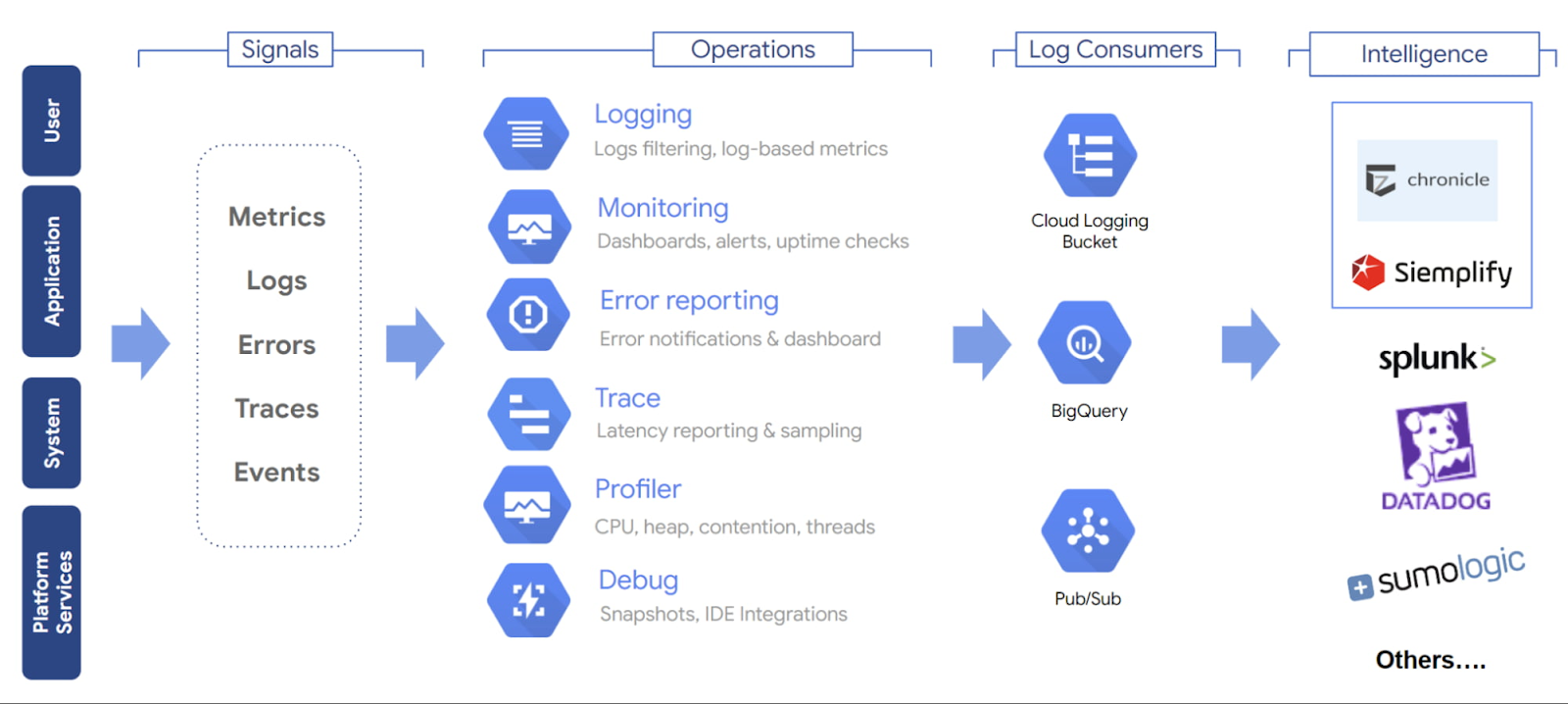
Following up with documentation: Observability on Google cloud
- Uptime check
Block: Data Security¶
[14] Initiative: Security¶
Data Access Policy IAM, service accounts Firewalls Policy
[15] Initiative: CICD for data-pipeline¶
We increased more and more CICD process to managage the internal flow.
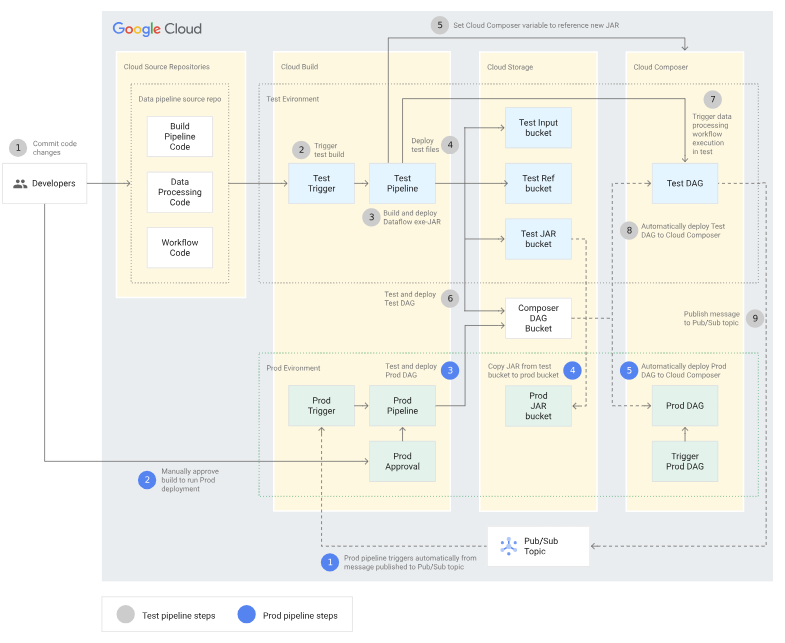
-
Coverage Check
-
Version control of source code.
-
Automatic building, testing, and deployment of apps.
-
Environment isolation and separation from production.
-
Replicable procedures for environment setup.
With:
-
More controlable: approval process
-
More specific supported fast deployment with out caring.
[16] Initiative: Developers Folder: for seperated environment on testing infrastructure¶
Seperated environment when test component of infrastructure
Block: Development Resource¶
[17] Initiative: Documentation Platform¶
Using the current element
Confluent: Limited User (10 in size - which affected) ~ required $850/year to handle that
Inno-Docs: Unlimited User (100 in size of the company) ~ required 1-2 server on that
[18] Initiative: GitHub¶
Based on the next-generation, we focus on protected the branch on CICD progress and multiple reviewers request.
[19] Initiative: Communication¶
- For the communication
| Type | Pros | Cons |
|---|---|---|
| Skype | Official channel | Channel with message based |
| Slack | Thread based | Pricing model affected (9\(/month/user ~ 100\)) |
| Discord | Pricing Free, , Thread-based, Transform time | Small configuration |
[20] Initiative: Project Software Development Tool¶
We propose for internal project development tools, based on the choosen options between Jira (official from company) and Linear We prefer Linear because:
-
It's not limited users (based on Issues) - which is the pricing models
-
It's can interchange with internal Jira
-
It's design related to development
Here is the sample display, which focused on the developers.
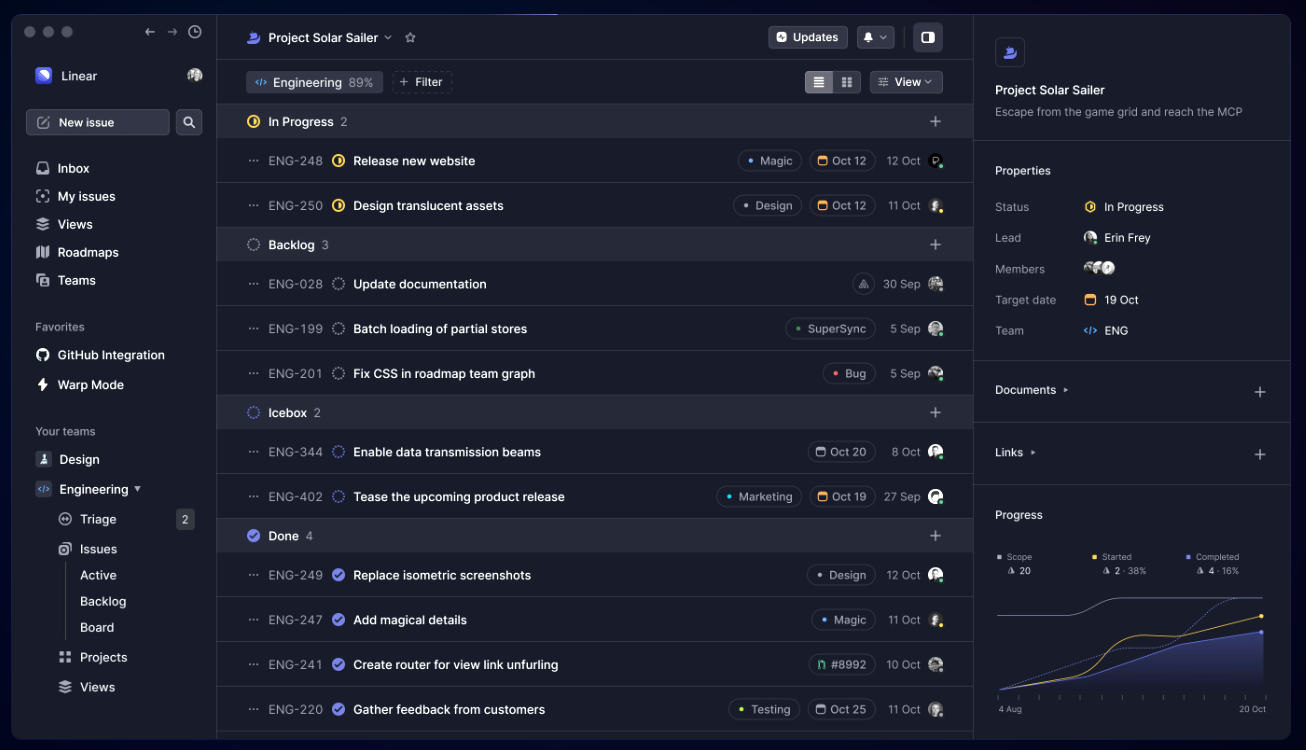
Physical Component¶
Physical on Services, Servers, Resources, external Platfrom
| Group | Usage | Cost Style | Expected Monthly Cost |
|---|---|---|---|
Team Focus¶
Developer productivity is basically how efficiently developers create valuable products and services.
- Increase developer productivity Focus on team capacipility and increased team velocity
For the next-generation for the data team, the team members in the groups requested to:
-
Faster Innovation Boosts competitive edge by reducing development time.
-
Higher Quality Products Leads to fewer bugs, happier customers.
-
Employee Satisfaction Happy developers are more engaged and productive.
-
Cost Savings Streamlines workflows, reduces operational expenses.
-
Scalability and Growth Enables efficient scaling and adaptation to market changes.
Into that, our team requested to (and it should be):
[A] Increase base benefit for development team
[B] Request for a default set of tools, machine (laptop, computer screen)
[C] Hybrid mode on working environments.
[D] Construct the more reliable metrics on project
[E] Continuous learning: within team, we will propose more internal seminar for sharing and prepair certificate
Certificate:
| Certificate | Description |
|---|---|
| Certified Kubernetes Application Developer (CKAD) | Design, build and deploy cloud-native applications for Kubernetes |
| Prometheus Certified Associate (PCA) | Observability and monitoring |
| Terraform 002 | Basic concepts and skills associated with open source HashiCorp Terraform. |
| Terraform 003 | Terraform 002 (2 times) on HashiCorp Terraform. |
| Google Certificate |
This required funding based on personal account or organzation level.
On long-learn and to enhance knowledge, I suggest having the fund for learning:
(a) Google Cloud Skill Boots: Google Cloud Skills Boost
(b) Some courses in VietNam for Machine Learning: such as NLP courses.