Conception about API¶
Overview¶
API is shortcut of Application Programming Interface - which are mechanisms that enable two software components to communicate with each other using a set of definitions and protocol.
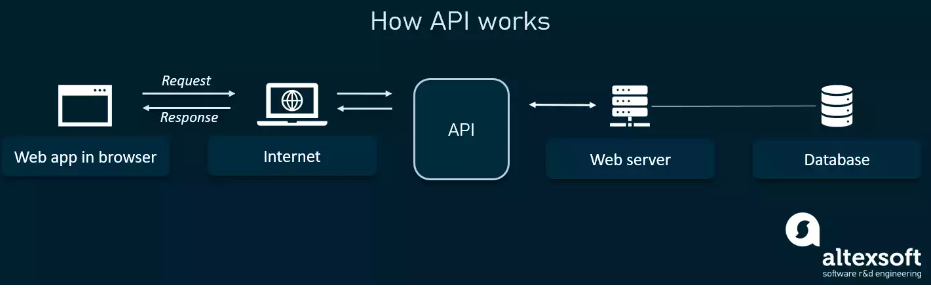
Ref: What is an API?
Standard¶
At the organination level, we following standard of following RFC documentation
HTTP Methods¶
This has been captured at MDN HTTP Method
HTTP defines a set of request methods to indicate the desired action to be performed for a given resource. Although they can also be nouns, these request methods are sometimes referred to as HTTP verbs. Each of them implements a different semantic, but some common features are shared by a group of them: e.g. a request method can be safe, idempotent, or cacheable.
| Method | Description |
|---|---|
| GET | The GET method requests a representation of the specified resource. Requests using GET should only retrieve data |
| HEAD | The HEAD method asks for a response identical to a GET request, but without the response body |
| POST | The POST method submits an entity to the specified resource, often causing a change in state or side effects on the server |
| PUT | The PUT method replaces all current representations of the target resource with the request payload |
| DELETE | The DELETE method deletes the specified resource |
| CONNECT | The CONNECT method establishes a tunnel to the server identified by the target resource |
| OPTIONS | The OPTIONS method describes the communication options for the target resource |
| TRACE | The TRACE method performs a message loop-back test along the path to the target resource |
| PATCH | The PATCH method applies partial modifications to a resource |
Status Code¶
Status code helps the developer implement API to know the situation when sending the request(s) to the server.
List of HTTP response status codes from OpenFIGI API, following and extending the standardized rule.
Q: How do you know when to yield status code, and which codes should be returned?
A: The status code when you finish a task from requests from users, or when hit any errors.
The status code must be meaningful, because its used by another systems.
The status codes from MDN documents are useful:
HTTP response status codes indicate whether a specific HTTP request has been successfully completed. Responses are grouped in five classes:
[+] Informational responses (100 – 199)
[+] Successful responses (200 – 299)
[+] Redirection messages (300 – 399)
[+] Client error responses (400 – 499)
[+] Server error responses (500 – 599)
For more detail: HTTP response status codes
The FastAPI has supported this too, read through Response Status Code
Design an API¶
This design go to basic protocol to create an API endpoint from the scratch
Following topics are required to build, develop this project
[1] API: Introduction, Why, How
[2] What information are required to gather before you develop? With and without Business Analyst?
[3] API Concentps from VEEAM: VEEAM REST Methods
[5] HTTPs methods progress
a) For GET
-
Arguments Parsing
-
Validate Elements
-
Construct DML Query
-
Returned response
b) For POST | PUT
-
Arguments Parsing
-
Validate Elements
[1] Check coi có exists True/False Routes [2] Fetching data {current} Routes [3] User update requirement {mapping-change} Routes [4] Update component CRUD
-
Construct DML Query
-
Returned response
c) For DELETE
-
Arguments Parsing
-
Validate Elements
-
Construct DML Query
-
Returned response
[5] Design Response Output:
a) For GET
List of Base Metadata
b) For POST | PUT
Returned body of item
c) For DELETE
Status of events
[Progress] When update new schema for model
CRUD 4 ways
11
Summary Use PUT to create or replace the state of the target resource with the state defined by the representation enclosed in the request. That intended effect is standardized and idempotent so it informs intermediaries that they can repeat a request in case of communication failure. Use POST otherwise (including to create or replace the state of a resource other than the target resource). The intended effect is not standardized so intermediaries cannot assume any property.
PUT The HTTP PUT request method creates a new resource or replaces a representation of the target resource with the request payload.
The difference between PUT and POST is that PUT is idempotent: calling it once or several times successively has the same effect (that is no side effect), whereas successive identical POST requests may have additional effects, akin to placing an order several times.
Request has body Yes Successful response has body May Safe No Idempotent Yes Cacheable No Allowed in HTML forms No
https://stackoverflow.com/questions/630453/what-is-the-difference-between-post-and-put-in-http
https://www.rfc-editor.org/rfc/rfc9110#PUT
I'd always prefer to keep PUT method idempotent. Idempotency can be explained as how many times you apply a certain "operation", the result will be the same as the first time. Since REST is just a style, it's up to you, but I will always question to me if it makes sense to keep the operation as PUT or POST.
What if the client of your service is impatient and access your PUT service multiple times while the first request is being served?. You may end up creating two users. So throwing an exception is meaningful if the ID doesn't exist.
It can be 400 or 404, I don't prefer 404 but prefer 400 because of the following reasons,
-
It confuses the client of your APIs if the resource is wrong or the ID they are using is wrong. (You can always differentiate in your error response and provide meaningful information, but still, I don't prefer!)
-
By using 404,
you're telling the user the problem could be permanent or temporary
,for instance, say your service is not properly registered with discovery server(eureka) or is crashed, the discovery server will send 404 until you fix the problem.
By using 400,
you're asking the user to try with different input, in this case, with a different ID. This is permanent...
as you said id is auto-increment and the client cannot decide the value, so until the user fixes the problem by going back and request your POST service for a new ID, the request is "BAD" and cannot be processed.
141
For those looking for the fastest way, I recently came across these benchmarks where apparently using "INSERT SELECT... EXCEPT SELECT..." turned out to be the fastest for 50 million records or more.
Here's some sample code from the article (the 3rd block of code was the fastest):
INSERT INTO #table1 (Id, guidd, TimeAdded, ExtraData) SELECT Id, guidd, TimeAdded, ExtraData FROM #table2 WHERE NOT EXISTS (Select Id, guidd From #table1 WHERE #table1.id = #table2.id)
MERGE #table1 as [Target] USING (select Id, guidd, TimeAdded, ExtraData from #table2) as [Source] (id, guidd, TimeAdded, ExtraData) on [Target].id =[Source].id WHEN NOT MATCHED THEN INSERT (id, guidd, TimeAdded, ExtraData) VALUES ([Source].id, [Source].guidd, [Source].TimeAdded, [Source].ExtraData);
INSERT INTO #table1 (id, guidd, TimeAdded, ExtraData) SELECT id, guidd, TimeAdded, ExtraData from #table2 EXCEPT SELECT id, guidd, TimeAdded, ExtraData from #table1
INSERT INTO #table1 (id, guidd, TimeAdded, ExtraData) SELECT #table2.id, #table2.guidd, #table2.TimeAdded, #table2.ExtraData FROM #table2 LEFT JOIN #table1 on #table1.id = #table2.id WHERE #table1.id is null
0
If you want to check whether a key exists or not, you can use:
INSERT INTO tableName (...) VALUES (...) ON DUPLICATE KEY UPDATE ...
RFC 9110 HTTP Semantics Abstract The Hypertext Transfer Protocol (HTTP) is a stateless application-level protocol for distributed, collaborative, hypertext information systems. This document describes the overall architecture of HTTP, establishes common terminology, and defines aspects of the protocol that are shared by all versions. In this definition are core protocol elements, extensibility mechanisms, and the "http" and "https" Uniform Resource Identifier (URI) schemes.
This document updates RFC 3864 and obsoletes RFCs 2818, 7231, 7232, 7233, 7235, 7538, 7615, 7694, and portions of 7230.
For POST¶
-
Can be use to CREATE or QUERY or UPDATE the dataset
-
Method:
[+] For submarine
- Can create multiple records, if not hit the integrity
http://restalk-patterns.org/post-put.html
https://stackoverflow.com/questions/56240547/should-http-put-create-a-resource-if-it-does-not-exist
CREATE IF NOT EXIST
Add header https://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.30
The Location response-header field is used to redirect the recipient to a location other than the Request-URI for completion of the request or identification of a new resource. For 201 (Created) responses, the Location is that of the new resource which was created by the request. For 3xx responses, the location SHOULD indicate the server's preferred URI for automatic redirection to the resource. The field value consists of a single absolute URI.
Location = "Location" ":" absoluteURI
An example is:
Location: http://www.w3.org/pub/WWW/People.html
Note: The Content-Location header field (section 14.14) differs
from Location in that the Content-Location identifies the original
location of the entity enclosed in the request. It is therefore
possible for a response to contain header fields for both Location
and Content-Location. Also see section 13.10 for cache
requirements of some methods.
# Validate
# (a) Check the items is already for {ticker}
# (b) Don't modified the component itself (id, status, timestamp, recogized)
# (c) Handle using bulk insert with returnning https://docs.sqlalchemy.org/en/20/orm/queryguide/dml.html#orm-queryguide-bulk-insert
POST - PUT can handle a single resource
Transfer to OLTP control
[1] ORM model changing
- SCD2 (id - PK) -> Build PK based on model
- MySQL (non-primary key với - id incremetal) -> handle UUID
[2] CRUD method
@router.get(
path="/quote",
description="Get quote",
summary="Get quote",
status_code=status.HTTP_200_OK,
response_model=BatchInnoQuoteResponse,
)
def fetchHistoricalQuote( <------ change to camelCase
- Handle schema (1) Proto
Model (2) Database Model (3) Batch ResponseModel
[2a] POST Model (https://datatracker.ietf.org/doc/html/rfc2616)
(a) Check exist status
(b) If exist -> raise HTTP error status 303
© Non-exist -> Insert (normal method) -> commit
(d) Re-fechting to get the UUID
(e) Add header Location with uuid HTTP construct
[2b] PUT Model (https://datatracker.ietf.org/doc/html/rfc2616)
(a) Check exist status
(b) If exist -> UPDATE -> 200
© If non-exist -> INSERT -> 201
(status code)
-> Safe action
[3] POST /bulk/insert (Design - Innotech compilance)
config: IF_DUPLICATE_THEN_ERROR, UPSERT(on DUPLICATE then UPDATE), on DUPLICATE do NOTHING
-
Bulk insert | Bulk Update
-
Based on config do different action
[4] PUT handler for FILE
[7] Apporval
POST /inno/quote/appoval -> UUID
BODY: Contain at least (UUID or PK (ticker-date))
Method:
-[0] Pass throguhed IAP model (none)
a) Check headers X-Requested-By:
principal: Email | trthuyetbao@innotech.vn
Client: midlleware -> Authenticated -> Added -> user -> https://nextjs.org/docs/app/building-your-application/routing/middleware#setting-headers
Server: If missing the headers -> Rejected -> 403
b) Check on permissions related (constant)
c) If approvaled already -> return 204
else d) UPDATE -> is_apporval = 1, approval_by = principal, approval_at = datetime (UTC) -> e) Return 200 OK
Pagination¶
https://cloud.ibm.com/docs/api-handbook?topic=api-handbook-pagination#token-based-pagination
Bulk/Batch insert/update¶
https://www.mscharhag.com/api-design/bulk-and-batch-operations
Supporting bulk operations in REST APIs Bulk (or batch) operations are used to perform an action on more than one resource in single request. This can help reduce networking overhead. For network performance it is usually better to make fewer requests instead of more requests with less data.
However, before adding support for bulk operations you should think twice if this feature is really needed. Often network performance is not what limits request throughput. You should also consider techniques like HTTP pipelining as alternative to improve performance.
When implementing bulk operations we should differentiate between two different cases:
Bulk operations that group together many arbitrary operations in one request. For example: Delete product with id 42, create a user named John and retrieve all product-reviews created yesterday. Bulk operations that perform one operation on different resources of the same type. For example: Delete the products with id 23, 45, 67 and 89. In the next section we will explore different solutions that can help us with both situations. Be aware that the shown solutions might not look very REST-like. Bulk operations in general are not very compatible with REST constraints as we operate on different resources with a single request. So there simply is no real REST solution.
In the following examples we will always return a synchronous response. However, as bulk operations usually take longer to process it is likely you are also interested in an asynchronous processing style. In this case, my post about asynchronous operations with REST might also be interesting to you.
Expressing multiple operations within the request body Probably a way that comes to mind quickly is to use a standard data format like JSON to define a list of desired operations.
Let's start with a simple example request:
POST /batch [ { "path": "/products", "method": "post", "body": { "name": "Cool Gadget", "price": "$ 12.45 USD" } }, { "path": "/users/43", "method": "put", "body": { "name": "Paul" } }, ... ] We use a generic /batch endpoint that accepts a simple JSON format to describe desired operations using URIs and HTTP methods. Here, we want to execute a POST request to /products and a PUT request to /users/43.
A response body for the shown request might look like this:
[ { "path": "/products", "method": "post", "body": { "id": 123, "name": "Cool Gadget", "price": "$ 12.45 USD" }, "status": 201 }, { "path": "/users/43", "method": "put", "body": { "id": 43, "name": "Paul" }, "status": 200 }, ... ] For each requested operation we get a result object containing the URI and HTTP method again. Additionally we get the status code and response body for each operation.
This does not look too bad. In fact, APIs like this can be found in practice. Facebook for example uses a similiar approach to batch multiple Graph API requests.
However, there are some things to consider with this approach:
How are the desired operations executed on the server side? Maybe it is implemented as simple method call. It is also possible to create a real HTTP requests from the JSON data and then process those requests. In this case, it is important to think about request headers which might contain important information required by the processing endpoint (e.g. authentication tokens, etc.).
Headers in general are missing in this example. However, headers might be important. For example, it is perfectly viable for a server to respond to a POST request with HTTP 201 and an empty body (see my post about resource creation). The URI of the newly created resource is usually transported using a Location header. Without access to this header the client might not know how to look up the newly created resource. So think about adding support for headers in your request format.
In the example we assume that all requests and responses use JSON data as body which might not always be the case (think of file uploads for example). As alternative we can define the request body as string which gives us more flexibility. In this case, we need to escape JSON double quotes which can be awkward to read:
An example request that includes headers and uses a string body might look like this:
[ { "path": "/users/43", "method": "put", "headers": [{ "name": "Content-Type", "value": "application/json" }], "body": "{ \"name\": \"Paul\" }" }, ... ] Multipart Content-Type for the rescue? In the previous section we essentially translated HTTP requests and responses to JSON so we can group them together in a single request. However, we can do the same in a more standardized way with multipart content-types.
A multipart Content-Type header indicates that the HTTP message body consists of multiple distinct body parts and each part can have its own Content-Type. We can use this to merge multiple HTTP requests into a single multipart request body.
A quick note before we look at an example: My example snippets for HTTP requests and responses are usually simplified (unnecessary headers, HTTP versions, etc. might be skipped). However, in the next snippet we pack HTTP requests into the body of a multipart request requiring correct HTTP syntax. Therefore, the next snippets use the exact HTTP message syntax.
Now let's look at an example multipart request containing two HTTP requests:
1 POST http://api.my-cool-service.com/batch HTTP/1.1 2 Content-Type: multipart/mixed; boundary=request_delimiter 3 Content-Length:
Quoting the RFC:
The encapsulation boundary is defined as a line consisting entirely of two hyphen characters ("-", decimal code 45) followed by the boundary parameter value from the Content-Type header field.
In line 2 we set the Content-Type to multipart/mixed with a boundary parameter of request_delimiter. The blank line after the Content-Length header separates HTTP headers from the body. The following lines define the multipart request body.
We start with the encapsulation boundary indicating the beginning of the first body part. Next follow the body part headers. Here, we set the Content-Type header of the body part to application/http which indicates that this body part contains a HTTP message. We also set a Content-Id header which we can be used to identify a specific body part. We use a client generated UUID for this.
The next blank line (line 8) indicates that now the actual body part begins (in our case that's the embedded HTTP request). The first body part ends with the encapsulation boundary at line 16.
After the encapsulation boundary, follows the next body part which uses the same format as the first one.
Note that the encapsulation boundary following the last body part contains two additional hyphens at the end which indicates that no further body parts will follow.
A response to this request might follow the same principle and look like this:
1 HTTP/1.1 200 2 Content-Type: multipart/mixed; boundary=response_delimiter 3 Content-Length:
Multipart messages seem like a nice way to merge multiple HTTP messages into a single message as it uses a standardized and generally understood technique.
However, there is one big caveat here. Clients and the server need to be able to construct and process the actual HTTP messages in raw text format. Usually this functionality is hidden behind HTTP client libraries and server side frameworks and might not be easily accessible.
Bulk operations on REST resources In the previous examples we used a generic /batch endpoint that can be used to modify many different types of resources in a single request. Now we will apply bulk operations on a specific set of resources to move a bit into a more rest-like style.
Sometimes only a single operation needs to support bulk data. In such a case, we can simply create a new resource that accepts a collection of bulk entries.
For example, assume we want to import a couple of products with a single request:
POST /product-import [ { "name": "Cool Gadget", "price": "$ 12.45 USD" }, { "name": "Very cool Gadget", "price": "$ 19.99 USD" }, ... ] A simple response body might look like this:
[ { "status": "imported", "id": 234235
},
{
"status": "failed"
"error": "Product name too long, max 15 characters allowed"
},
...
] Again we return a collection containing details about every entry. As we provide a response to a specific operation (importing products) there is not need to use a generic response format. Instead, we can use a specific format that communicates the import status and potential import errors.
Partially updating collections In a previous post we learned that PATCH can be used for partial modification of resources. PATCH can also use a separate format to describe the desired changes.
Both sound useful for implementing bulk operations. By using PATCH on a resource collection (e.g. /products) we can partially modify the collection. We can use this to add new elements to the collection or update existing elements.
For example we can use the following snippet to modify the /products collection:
PATCH /products [ { "action": "replace", "path": "/123", "value": { "name": "Yellow cap", "description": "It's a cap and it's yellow" } }, { "action": "delete", "path": "/124", }, { "action": "create", "value": { "name": "Cool new product", "description": "It is very cool!" } } ] Here we perform three operations on the /products collection in a single request. We update resource /products/123 with new information, delete resource /products/124 and create a completely new product.
A response might look somehow like this:
[ { "action": "replace", "path": "/123", "status": "success" }, { "action": "delete", "path": "/124", "status": "success" }, { "action": "create", "status": "success" } ] Here we need to use a generic response entry format again as it needs to be compatible to all possible request actions.
However, it would be too easy without a huge caveat: PATCH requires changes to be applied atomically.
The RFC says:
The server MUST apply the entire set of changes atomically and never provide [..] a partially modified representation. If the entire patch document cannot be successfully applied, then the server MUST NOT apply any of the changes.
I usually would not recommend to implement bulk operation in an atomic way as this can increase complexity a lot.
A simple workaround to be compatible with the HTTP specifications is to create a separate sub-resource and use POST instead of PATCH.
For example:
POST /products/batch (same request body as the previous PATCH request)
If you really want to go the atomic way, you might need to think about the response format again. In this case, it is not possible that some requested changes are applied while others are not. Instead you need to communicate what requested changes failed and which could have been applied if everything else would have worked.
In this case, a response might look like this:
[ { "action": "replace", "path": "/123", "status": "rolled back" }, { "action": "delete", "path": "/124", "status": "failed", "error": "resource not found" }, .. ] Which HTTP status code is appropriate for responses to bulk requests? With bulk requests we have the problem than some parts of the request might execute successfully while other fail. If everything worked it is easy, in this case we can simply return HTTP 200 OK.
Even if all requested changes fail it can be argued that HTTP 200 is still a valid response code as long as the bulk operation itself completed successfully.
In either way the client needs to process the response body to get detailed information about the processing status.
Another idea that might come in mind is HTTP 207 (Multi-status). HTTP 207 is part of RFC 4918 (HTTP extensions for WebDAV) and described like this:
A Multi-Status response conveys information about multiple resources in situations where multiple status codes might be appropriate. [..] Although '207' is used as the overall response status code, the recipient needs to consult the contents of the multistatus response body for further information about the success or failure of the method execution. The response MAY be used in success, partial success and also in failure situations.
So far this reads like a great fit.
Unfortunately HTTP 207 is part of the Webdav specification and requires a specific response body format that looks like this:
1 2 3 4 5 6 7 8
In case you the bulk request is processed asynchronously HTTP 202 (Accepted) is the status code to use.
Summary We looked at different approaches of building bulk APIs. All approaches have different up- and downsides. There is no single correct way as it always depends on your requirements.
If you need a generic way to submit multiple actions in a single request you can use a custom JSON format. Alternatively you can use a multipart content-type to merge multiple requests into a single request.
You can also come up with separate resources that that express the desired operation. This is usually the simplest and most pragmatic way if you only have one or a few operations that need to support bulk operations.
In all scenarios you should evaluate if bulk operations really produce the desired performance gains. Otherwise, the additional complexity of bulk operations is usually not worth the effort.
https://copyprogramming.com/howto/restful-api-and-bulk-operations
POST | PUT quote/bulk/import
Note¶
(a) Not handle user input (Not to de-duplication) -> Handle Pydantic
Constraint¶
(a) Multiple status code -> Status: HTTP 207 Multi Status Follow: https://www.javacodegeeks.com/2021/05/supporting-bulk-operations-in-rest-apis.html
(b) Lock down total item for POST/PUT of bulk into MAXIMUM_ITEM | -> (100 | 200)
POST -> Insert by record step by step
status: "ok"
for ind, component in enumuration(, start=1):
start = datetime.now()
_operation_id: int = ind
_operation_total_ms: float = <total-time>
+ Execute like POST for single
+ If exist -> FAILED -> status: status: (303) -> state = FAILED
+ If non exist -> INSERT -> status: 201 -> state = CREATED
+ Re-fetch -> Location: UUID (handle) ____
_operation_total_ms = (datetime.now() - start).total_seconmds() * 1000
For the output: Follow https://dev.wix.com/docs/rest/api-reference/media/media-manager/files/import-file
Output { id: UUID4 status: ok, total_time:
https://is.docs.wso2.com/en/6.0.0/guides/identity-lifecycles/bulk-import-users/
https://knowledge.informatica.com/s/article/565974?language=en_US
Process¶
API Endpoint:
GET | POST | PUT | DELETE
URL: /inno/settlement
Database Mapping: inno_settlement
country: string date: date timezone: string (Asia/Ho_Chi_Minh) name: string
Repository: https://github.com/Innotech-Vietnam/inno-submarine
~> Basement | Python script use the ifc (inno_finance_core) to add data into inno/settlement
import inno_finance_core as ifc
for loop: ifc.SETTTLEMENT_CLOSING_DATE ~> Use GET to INSERT
~> Python Submarine Client | Endpoint
import submarine as sm client = sm.Client() client.inno.settlement.post()
bump version ~> 1 minor x.x.[minor]
~> LakePrep: ~> ()
~> Inno-Spectrum
Transfer to OLTP control
[1] ORM model changing
- SCD2 (id - PK) -> Build PK based on model
- MySQL (non-primary key với - id incremetal) -> handle UUID
[2] CRUD method
@router.get(
path="/quote",
description="Get quote",
summary="Get quote",
status_code=status.HTTP_200_OK,
response_model=BatchInnoQuoteResponse,
)
def fetchHistoricalQuote( <------ change to camelCase
- Handle schema (1) Proto
Model (2) Database Model (3) Batch ResponseModel
[2a] POST Model (https://datatracker.ietf.org/doc/html/rfc2616)
(a) Check exist status
(b) If exist -> raise HTTP error status 303
© Non-exist -> Insert (normal method) -> commit
(d) Re-fechting to get the UUID
(e) Add header Location with uuid HTTP construct
[2b] PUT Model (https://datatracker.ietf.org/doc/html/rfc2616)
(a) Check exist status
(b) If exist -> UPDATE -> 200
© If non-exist -> INSERT -> 201
(status code)
-> Safe action
[3] POST /bulk/insert (Design - Innotech compilance)
config: IF_DUPLICATE_THEN_ERROR, UPSERT(on DUPLICATE then UPDATE), on DUPLICATE do NOTHING
-
Bulk insert | Bulk Update
-
Based on config do different action
[4] PUT handler for FILE
[7] Apporval
POST /inno/quote/appoval -> UUID
BODY: Contain at least (UUID or PK (ticker-date))
Method:
-[0] Pass throguhed IAP model (none)
a) Check headers X-Requested-By:
principal: Email | trthuyetbao@innotech.vn
Client: midlleware -> Authenticated -> Added -> user -> https://nextjs.org/docs/app/building-your-application/routing/middleware#setting-headers
Server: If missing the headers -> Rejected -> 403
b) Check on permissions related (constant)
c) If approvaled already -> return 204
else d) UPDATE -> is_apporval = 1, approval_by = principal, approval_at = datetime (UTC) -> e) Return 200 OK
Source Reference¶
[1] HTTP response status codes from MDN: MDN status code explain
-
Design concepts: WSO2
https://cloud.ibm.com/docs/api-handbook?topic=api-handbook-methods